
对话自变量王潜:错过图灵奖,要做具身界的 OpenAI
对话自变量王潜:错过图灵奖,要做具身界的 OpenAI王潜说,DeepSeek 当然很伟大,但我们要干一个像 OpenAI 那样的公司。
来自主题: AI资讯
11323 点击 2026-01-19 16:44
 搜索
搜索
王潜说,DeepSeek 当然很伟大,但我们要干一个像 OpenAI 那样的公司。
2026 年 1 月过半,我们依然没有等来 DeepSeek V4,但它的模样已经愈发清晰。
新年第一天,DeepSeek 发布了一篇艰深晦涩的技术论文,不少网友直呼「看不懂」。

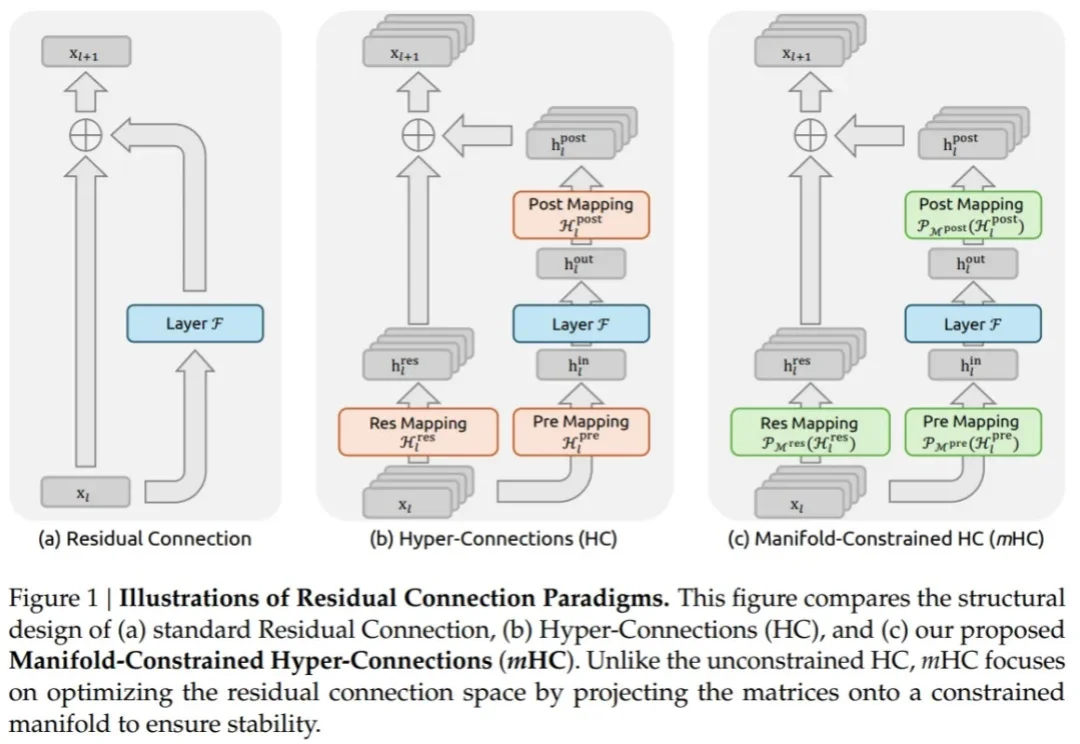
深夜,梁文锋署名的DeepSeek新论文又来了。这一次,他们提出全新的Engram模块,解决了Transformer的记忆难题,让模型容量不再靠堆参数!

今天凌晨,喜欢闷声做大事的 DeepSeek 再次发布重大技术成果,在其 GitHub 官方仓库开源了新论文与模块 Engram,论文题为 “Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models”, 梁文锋再次出现在合著者名单中。

前几天元旦,DeepSeek 又激发了「假期更新」 Buff,梁文锋署名新论文刷屏 AI 圈,就在大家都在等待 V4 的发布时,我发现有一群人早就在 DeepSeek 里找到了新乐子:自制「橙光游戏」。

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。
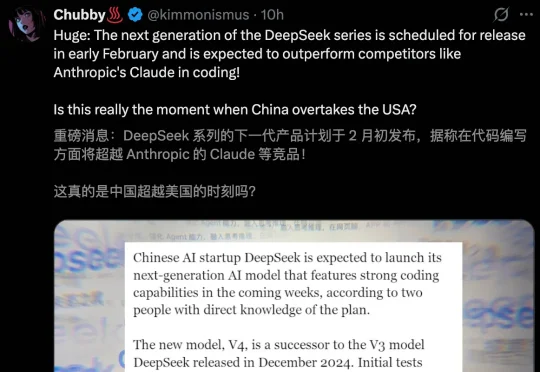
Information爆料称,DeepSeek将计划在2月中旬,也正是春节前后,正式发布下一代V4模型。据称,DeepSeek V4编程实力可以赶超Claude、GPT系列等顶尖闭源模型。
两天前,DeepSeek悄无声息地把R1的论文更新了,从原来22页「膨胀」到86页。DeepSeek向世界证明:开源不仅能追平闭源,还能教闭源做事!

最近,APPSO 终于拿到了这台来自黄仁勋倾情推荐的个人超算,英伟达 DGX Spark;到手的第一感觉,就是「小而美」。这电脑也太小了,没有 Mac Studio 那般笨重,可能就和 Mac Mini 差不多大;然后是银色的亮和用来散热的金属丝网又让它有点不一样,是专属的硬核美感。